x86架构下μop是如何调度的
在CPU的后端会有多个port用于执行uop。每个port只能用于执行某些uop,而一条uop可能可以在多个port执行,这就涉及到了uop的调度问题。
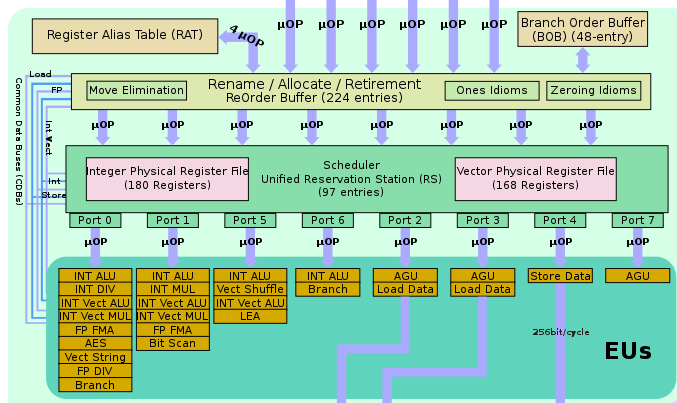
后端结构
以skylake为例,具体结构如下。如果需要查阅具体的某条指令在哪些port上执行,可以参考agner的instruction_table。比如icelake架构下 mov 指令可以在0156四个端口上执行。
理论调度规则
以下部分翻译自 Abel, Andreas. “Accurate Throughput Prediction of Basic Blocks on Recent Intel Microarchitectures.” Arxiv:2107.14210 [Cs], n.d.
端口在uop被分配到scheduler的时候就确定了(我认为这暗示了端口分配是由renamer完成的)。在一个周期中,最多可以发布4个uop。在下文中,把一个周期内的uop的位置称为
issue slot;例如,在一个周期中最早发布的指令将占用issue slot 0。一个uop被分配的端口取决于它的issue slot和上一轮中uop(被发布但是还没有执行的uop)去往的端口。以下的uop都指可以在多个端口上执行的uop。对于一条给定的uop $m$,$P_{min}$ 是 $m$ 所能使用的所有端口中被分配到最少的未执行的uop的端口。 $P_{min’}$ 是目前使用次数第二少的端口。如果有多个$P_{min}$ (或者$P_{min’}$ ),那么$P_{min}$ (或者$P_{min’}$ )是端口号码更高的那个,这是因为更高的端口号码功能更少(见后端结构图)。如果 $P_{min}$ 和 $P_{min’}$ 的差值大于等于3,将 $P_{min’}$ 设置为 $P_{min}$ 。(这是为了减少二者的差值)
占用
issue slot 0和issue slot 2的uop会被分配到 $P_{min}$,占用issue slot 1和issue slot 3的uop会被分配到 $P_{min’}$。一个特殊情况是使用端口2和3的uop,这两个端口涉及到访存而且功能完全相同,所以二者是交替使用的。
实际运行中的调度
在实际运行中的大部分情况都符合调度规则,但是其他组件和CPU经过多年的迭代之后越来越多的内部未知行为(未在手册中进行描述)也可能会对调度产生影响。
上述论文的作者还有一个相应的网站可以模拟运行并预测基本块的吞吐量,但是对下面的corner case应对不好。代码仓库地址。
预测执行对调度的影响
使用Travis Downs的测试代码
1 | _start: |
查表可知,执行端口如下所示。其中dec和jnz会宏融合成一条指令,同时BPU会预测该指令将跳转。
| inst | port 0 | port 1 | port 5 | port 6 |
|---|---|---|---|---|
| xor r,r/i | √ | √ | √ | √ |
| add r,r/i | √ | √ | √ | √ |
| imul r64,r64,i | × | √ | × | × |
| predicted taken jump | × | × | × | √ |
实验结果如下所示,由于是采样,所以会有~3%的出入。
| port | 活跃周期 |
|---|---|
| p0 | 518,350,153 |
| p1 | 1,244,144,172 |
| p5 | 1,022,136,023 |
| p6 | 1,234,819,454 |
| total | 1,869,986,150 |
实验结果和预期是不相符合的(甚至是完全相悖的),按照理论调度规则,p0不应该周期数和p5有如此显著的差异。
一个可能的解释是renamer在确定端口的时候并不知道这个分支指令是会跳转的,所以对他来说p0和p6都是可供分配的,但是预测跳转的指令实际上只能在p6执行,所以p0的活跃周期数就下降了。
指令延迟对调度的影响
但是真的是由于预测执行的影响吗?再看一段代码
1 | _start: |
这一次代码的端口分布如下,每条指令的延迟均为1周期。(与之相对比的是 imul 的指令延迟是3周期)
延迟 (latency):从指令开始到结果可用的时间
吞吐量 (throughput):指当每条指令的操作数独立于前面的指令时,每个时钟周期可以执行的同类指令的最大数量。
吞吐量的倒数 (reciprocal throughput):假设在同一线程中有一系列相同类型且相互独立的指令,每条指令的平均核心时钟周期数。
比如
div r8的 reciprocal throughput 为 6,那么一条新的 div 指令可以在前一条指令开始 6 个周期后执行,而它的 latency 为 12,意味着结果需要 12 个周期才可用。再比如add r,r/i的 reciprocal throughput 为 0.25,这意味着同一周期可以执行 4 条独立的 add 指令。
| inst | port 0 | port 1 | port 5 | port 6 |
|---|---|---|---|---|
| xor r,r/i | √ | √ | √ | √ |
| ror r,1 | √ | × | × | √ |
| bswap r32 | × | √ | √ | × |
| predicted taken jump | × | × | × | √ |
这一次的实验结果如下,可以看到分布明显比上面的例子均匀了。
| port | 活跃周期 |
|---|---|
| p0 | 999,165,706 |
| p1 | 999,691,889 |
| p5 | 999,023,091 |
| p6 | 1,001,362,534 |
| total | 999,723,598 |
可以设想到有两个显然的因素会影响端口活跃周期,一个是指令理论可用的端口,另一个是指令的延迟。但是CPU具体是怎么考虑这二者的,我还没有思考清楚,也许之后我会重新完善这一小节。
计数器在线程间是否共享
由理论调度规则可知,renamer应该为每个端口都维护了一个计数器,那么这个计数器是否在线程间共享是一个有趣的话题。
一开始我以为这个计数器是维护了已执行的uop数量,但是重新阅读了理论调度规则之后,这个计数器应该维护的是已经发布(issue)但是还没有执行(non-executed)的uop数量。这就有一些鸡肋了,即使共享似乎切入的粒度要求也很高。
不妨将上面的代码拆成两个线程执行(具体代码参考之前的博客),nop_uop 称为线程1,regular_uop 称为线程2。
1 | nop_uop: |
其中指令 bswap 可以在端口1和5上执行,imul r64,r64,i 在端口1上执行。如果计数器在线程间共享,那么就会看到 bswap 在端口5上执行,imul 在端口1上执行。
实验记录如下,其中线程1的p0、p5端口和线程2的p0端口应该记录了少量非用户数据,但是不妨碍得到结论。从数据中还是可以清楚的看到,线程2的 bswap 指令在p1和p5端口之间交替执行,并没有出现让出p1的现象。
| port | 线程1活跃周期 | 线程2活跃周期 |
|---|---|---|
| p0 | 63,088,967 | 68,022,708 |
| p1 | 180,219,013,832 | 95,742,764,738 |
| p5 | 63,994,200 | 96,291,124,547 |
| p6 | 180,330,835,515 | 192,048,880,421 |
| total | 180,998,504,099 | 192,774,759,297 |
上述结论和SMotherSpectre5一文的结论并不冲突,该文使用的是时间作为侧信道。(以上面的代码为例的话就是线程2在端口1等待了更长时间才能使用端口1)
编辑:我在StackOverflow上提交了这一小节作为答案,有评论指出p6才是真正的端口压力所在,所以我将 imul 和 bswap 在单个循环中重复了39次,结论没有改变。
参考
- 1.Abel, Andreas. “Accurate Throughput Prediction of Basic Blocks on Recent Intel Microarchitectures.” Arxiv:2107.14210 [Cs], n.d. ↩
- 2.How are x86 uops scheduled, exactly? ↩
- 3.Skylake (client) - Microarchitectures - Intel ↩
- 4.Method and apparatus for binding instructions to dispatch ports of a reservation station ↩
- 5.Bhattacharyya, Atri, Alexandra Sandulescu, Matthias Neugschwandtner, Alessandro Sorniotti, Babak Falsafi, Mathias Payer, and Anil Kurmus. “SMoTherSpectre: Exploiting Speculative Execution through Port Contention.” Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, November 6, 2019, 785–800. https://doi.org/10.1145/3319535.3363194. ↩
x86架构下μop是如何调度的